 Large Language Models (LLMs) have exploded in popularity, and typically they run in massive datacenters operated by tech giants. But here on LowEndBox, we’re all about democratizing computing. Is it possible to run your own AI on a cheap VPS?
Large Language Models (LLMs) have exploded in popularity, and typically they run in massive datacenters operated by tech giants. But here on LowEndBox, we’re all about democratizing computing. Is it possible to run your own AI on a cheap VPS?
Yes!
Now, to be clear, you can’t self-host a digital brain the size of ChatGPT or Claude. Those models have billions upon billions of parameters and require a lot of specialized compute (GPU) to run. Even something like Llama 3, which is a generation back from Meta’s latest model, is not going to be happy without a GPU, and consumer GPUs push prices outside the LowEnd realm.
So how can we run an LLM on a LowEnd VPS? Quantization.
What is Quantization?
Quantization is the process of reducing the precision of the numbers used to represent a neural network’s weights and activations. Most AI models are originally trained using float32 (32-bit floating-point numbers). These offer high precision but consume lots of memory and compute. Quantization shrinks this down to 8-bit, 4-bit, or even fewer bits, drastically reducing the model size.
So instead of 232 possible values per weight, you get 24, which is 16 possible values. This can radically shrink the size of models and hence the amount of RAM they use.
Of course, there’s a tradeoff. Because of the loss of precision, you lose subtlety in the language and weaker performance on complex tasks. Or to put it more simply, a 4-bit model is not going to be anywhere as good as a 32-bit model.
In this example, we’ll be using TinyLlama, which is a 1.1B-parameter 4-bit LLM model.
What Kind of VPS Do You Need?
I’m going to be using a RackNerd VPS with these specs:
- 3 vCPU Cores
- 60 GB Pure SSD Storage
- 3.5 GB RAM
- 5TB Monthly Transfer
- Only $29.89/YEAR!
That’s only $2.49/month which is a fantastic deal. You can GET YOUR OWN HERE. I placed mine in Los Angeles, CA but these are available in multiple datacenters in North America, including San Jose, Seattle, Chicago, Dallas, New York, Ashburn, and Toronto.
Setup
I’m using Debian 12 and Ollama, a tool for running LLMs.
Ollama is not in apt. You have a couple options.
Option #1: Install Script (recommended)
There’s a nice self-install script from Ollama. This will install the product and configure it to start at boot.
I recommend going this route. All you need to do is:
- Go to ollama.com
- Click Download in the upper right
- Select Linux
- Click the copy icon on the script and paste it into a root shell
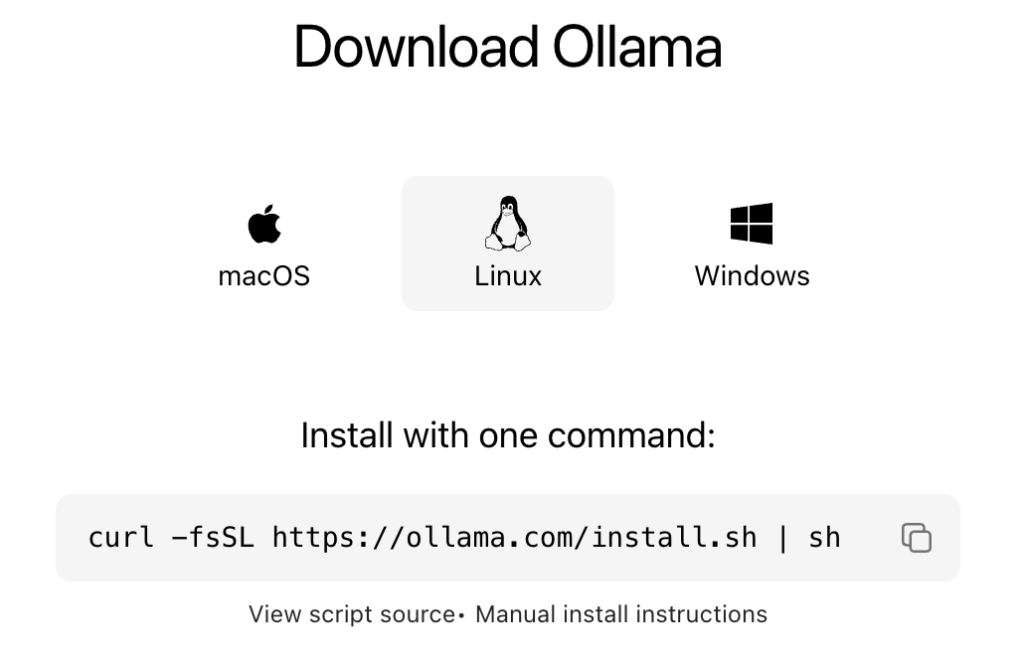
That will install Ollama, enable it, and start it.
Option #2: Homebrew Option
Ollama is in Homebrew. I initially went down this path but I’ve found Homebrew to be a bit awkward and buggy with Linux. It’s awesome on MacOS. But on Linux, it sets up a parallel systemd, and I kept running into errors and found others had the same experience. So again…almost mandatory for MacOS, but I prefer not to use it on Linux.
But if you want to try it out, perhaps your experience will be different (or perhaps I’m clueless).
To install Homebrew, visit brew.sh, copy the one-liner under “Install Homebrew,” and paste it in your Linux terminal. Homebrew will not mess with apt or your system package manager. You can have both Homebrew and apt running side by side with no issues. apt manages things it installs and Homebrew manages things it installs. My advice would be to use apt primarily, fill in anything missing with Homebrew, and don’t install the same packages with both.

Note: Homebrew will not install as root, so paste it in a non-root terminal. However, the user who’s installing Homebrew should have sudo capabilities. There are different ways to configure sudo, but the easiest is to install sudo (apt install sudo) and then add whatever user you’re using into the ‘sudo’ group in /etc/group.
Now install Ollama:
brew install ollama
Start Ollama:
brew services start ollamaTrying It Out
We need to get the TinyLlama LLM. Ollama makes this easy:
ollama pull tinyllama
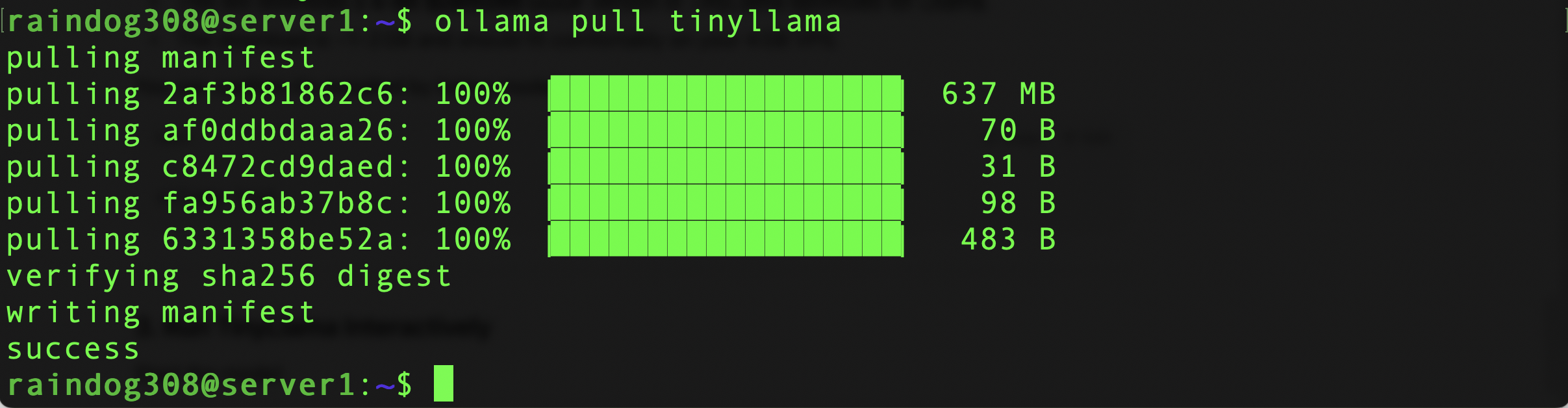
Now run it:
ollama run tinyllamaHere’s a video showing the experience of running a prompt. As you can see, it starts up quickly and output is pretty sprightly:
While this was running, the system was under heavy load:
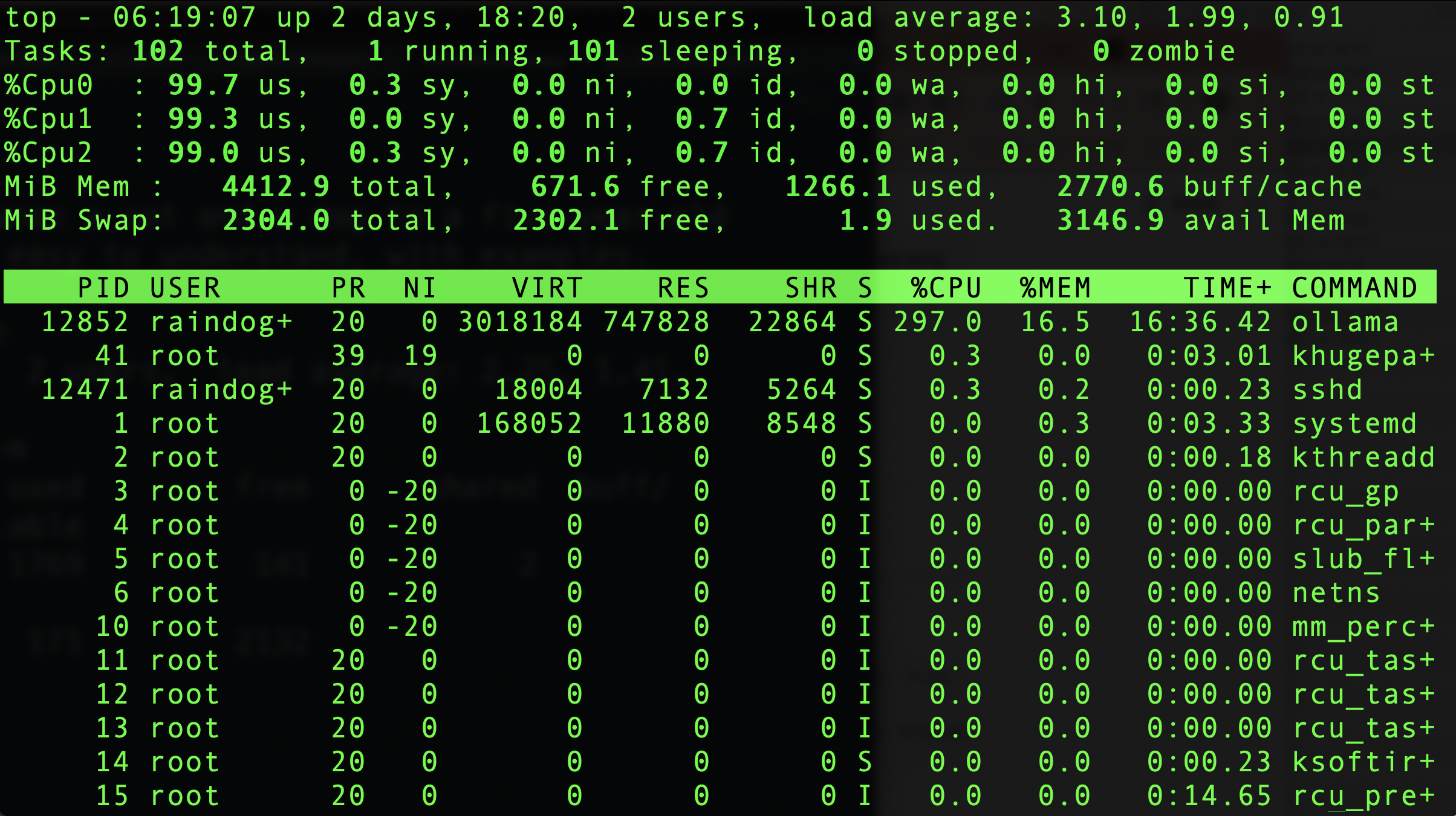
Still plenty of available RAM:

Now that we’ve got Ollama up and running, let’s turn this into a full-fledged web UI like ChatGPT. Stay tuned for part two!
Related Posts:
Why Oracle's Trouble in Wisconsin Is a Big Deal
HostNamaste: Dedicated Physical CPU • Enterprise SSD Storage • Windows & Linux • USA • Canada • Fran...
No Limit! New LowEndTalk Community Provider NolimitHost Has Some Nice Offers in Chicago and Frankfur...
ALMOST GONE! Get a BONUS CODE for ColoCrossing's Synology NAS, AirPods Max, Apple Watch, and MORE Gi...
AI VPS Demand Is Rising - Are Hosting Providers Ready?
Got Your Cheap Dedi Yet? Only $29/Month from ColoCrossing PLUS Here's a BONUS CODE to Help You Win a...
raindog308 is a longtime community LETizen, technical writer, and self-described techno polymath. With deep roots in the *nix world, he has a passion for systems both modern and vintage, ranging from Unix, Perl, Python, and Golang to shell scripting and mainframe-era operating systems like MVS. He’s equally comfortable with relational database systems, having spent years working with Oracle, PostgreSQL, and MySQL.
As an avid user of LowEndBox providers, raindog308 runs an empire of LEBs, from tiny boxes for VPNs, to mid-sized instances for application hosting, and heavyweight servers for data storage and complex databases. He brings both technical rigor and real-world experience to every piece he writes.
Beyond the command line, raindog308 has a life-long love of German Shepherd Dogs, high-quality knives, target shooting, theology, tabletop RPGs, playing guitar, and hiking in deep, quiet forests.
His goal with every article is to help users, from beginners to seasoned sysadmins, get more value, performance, and enjoyment out of their infrastructure.
You can find him daily in the forums at LowEndTalk under the handle @raindog308.


























Still waiting for part2.Interesting🤍
Ollama running on that instance without a GPU is still writing part 2. 😀