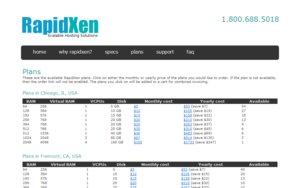
 We covered RapidXen before but unfortunately their $5/month 64MB Xen VPS is no longer available. Instead they have updated their Xen VPS plans with a base VPS that starts with $7.99/month. However if you prepay for a year you’ll get 25% off (promotion ends on 13 Nov 2008), which brings the price down to around $5.62/month. You get:
We covered RapidXen before but unfortunately their $5/month 64MB Xen VPS is no longer available. Instead they have updated their Xen VPS plans with a base VPS that starts with $7.99/month. However if you prepay for a year you’ll get 25% off (promotion ends on 13 Nov 2008), which brings the price down to around $5.62/month. You get:
- 128MB memory + 256MB swap
- 1 CPU core
- 5GB storage
- Unmetered data transfer
Their servers are in Fremont, CA with HE, or in Chicago, IL with Steadfast.
Related Posts:
ServerHost Offers 16GB KVM VPS with 240GB NVMe for $99.99/year — Only 100 Codes Available
High-Performance DirectAdmin Shared & Reseller Deals from Limitless Hosting, Starting at Only $3/YEA...
ServerHost LowEndBox Exclusive: 10 GB RAM VPS – Just $98.88 / Year!
NEWS: ColoCrossing Expands Buffalo Data Center to Support Growing Infrastructure Demands
A VPS For Only $7/YEAR in Chicago! Wow! Check Out TNAHosting!
Host4Fun: 50% Off in Over 20 Locations! Get an 8GB RAM VPS for Only $5/Month!
LEA (LowEndAdmin) is the original founder of LowEndBox and the visionary who gave rise to an entire movement around minimalist, efficient hosting. In 2008, LEA launched LowEndBox with a simple but powerful idea: that it was possible to run meaningful applications, web servers, VPNs, mail servers, and more – on small, low-cost virtual machines with minimal resources.
At a time when most infrastructure discussions were dominated by high-end servers and enterprise platforms, LEA championed the opposite approach: lightweight Linux distros, self-managed servers, open source software, and thoughtful optimization. This philosophy gave birth to the term “Low End Box”, which would come to define a new genre of hosting tailored to developers, tinkerers, and budget-conscious users around the world.
Through LowEndBox and its companion forum, LowEndTalk, LEA built the foundation for what would become one of the most active and enduring communities in the hosting world, prioritizing knowledge-sharing, transparency, and accessibility.
After several years of nurturing the site and community, LEA stepped away from active involvement, passing the torch to a new generation of admins, contributors, and moderators. Today, LEA remains a respected figure in the LowEnd ecosystem, credited with launching a platform and philosophy that continues to influence thousands of infrastructure providers and users globally.
LowEndBox’s legacy, and its thriving community, is a direct result of LEA’s original vision.
























I have one of the 64mb services, not sure if I’ll continue with it though.
All the VMs recently got wiped on the host I’m on, apparently an ex employee 🙁
Bit of an inconvenience to have to rebuild from scratch and my own backups.
Up until that point it has been a pretty decent service.
I’ve had a 64Mb account with RapidXen for a couple months now and have been very happy with their offering. I’m at their Fremont datacenter. At this point, I’m simply using the VPS as secondary DNS, but am so pleased, I’ll be getting one of their new 128Mb servers in Chicago and setting it up as a Centreon (http://www.centreon.com/) monitoring server. I presently have budget XEN VPS’s with VPSlink, RapidXEN, and VPSVillage. RapidXen is the best performer so far.
Regarding the VM’s getting wiped by an ex-employee, luckily my server wasn’t one that was touched. However, you should never keep data on a VPS without maintaining backups. Plus, after companies experience this type of internal security breach, they usually come back stronger and more secure than ever. I’m not dropping them.
Bad news. I miss the 64MB plan. 🙁
Actually, the base plan is $7.49/mo. (It is literally the old $5 plan with a 64MB upgraded added.)
We dropped the 64MB plan because there was a lot of overhead involving VPS running out of memory.
We will likely do another promotion soon to lock in a slightly cheaper price on both monthly and yearly pricing… we’re adding a bunch of new nodes around December 15th, and we will want to fill those up quickly. Stay tuned on that.
Are you providing 100mbit uplink?
I just wanted to post a follow up to my post 3 months ago. Since that time, I did in fact sign up for a 128MB plan at the Chicago datacenter. Only running PowerDNS(sqlite backend) for 7 domains, Lighttpd, and Cacti the server constantly bogged down due to I/O issues. My VPS used zero swap, and only minor CPU/RAM, so I can only attribute this to other users on the server. Since the default /etc/hosts file seems to contain all the IP addresses and names of accounts on the server (bad bad bad) at the time the guest is created, I determined I was roughly the 25th guest. After only two months I canceled.
Still being pleased with my old 64MB account at the Fremont datacenter, I’ve been keeping that one alive. It only ran PowerDNS(sqlite backend) for 8 domains and never had issues until the first of this year where I/O issues developed intermittently. After a dedicated tertiary DNS server failure, I decided to go ahead and move DNS for all my production domains (1800 of them) to this box and see how things fare. It actually handles them no problem with no backend connection failures.
Uptime: 3.13 days
Queries/second, 1, 5, 10 minute averages: 2.98, 2.79, 2.73.
Max queries/second: 17.3
Cache hitrate, 1, 5, 10 minute averages: 59%, 60%, 60%
Backend query cache hitrate, 1, 5, 10 minute averages: 48%, 51%, 52%
Backend query load, 1, 5, 10 minute averages: 1.8, 1.6, 1.57.
Max queries/second: 45.2
Total queries: 754044.
Question/answer latency: 8.49ms
However 🙁 after a recent “emergency kernel maintenance” by RapidXEN, I now experience 30-60 minutes of network downtime every day or two. Support staff “don’t see the problem” though I can verify the issue from all four corners of the US. Hopefully things resolve themselves soon. Service seems to be degrading. Just me or anyone else having the same problem? I almost feel guilty complaining about a $5/mo service.
Hi Ken,
Can you email me your account information or preferably get on our IRC channel and I will look into resolving this issue personally.
We had been having some DDoS issues in Fremont over the weekend. These should resolved now, at least we have not gotten any network alerts about it on nagios or smokeping.
In Chicago, some VPSes were on a storage node that was having some I/O problems due to a controller driver bug. We have since fixed that node and it is providing optimal performance:
skylar.internal: 100 MB in 3.07 seconds = 32.52 MB/sec
shadow.internal: 90 MB in 3.11 seconds = 28.95 MB/sec
hadar.internal: 72 MB in 3.26 seconds = 22.06 MB/sec
aurora.internal: 83 MB in 3.07 seconds = 27.03 MB/sec
As you can see, the above AoE volumes are within tolerance boundaries, especially considering that they are SAN-based storage volumes and not local.
(There are many reasons for this, mostly it allows us to temporarily migrate VMs to other nodes in the cluster while we do hardware level maintainance on a machine.)
Anyway, if you feel our service is degrading, I would love to hear constructive feedback on specific problems.
On the topic of I/O, we are working hard to deploy next-generation I/O scheduling in the hypervisor code at the moment to ensure fair-share I/O usage, with prioritization toward filesystem I/O, and have already implemented stricter I/O monitoring to find VPSes that are exceeding plan limitations (think 2GB /swapfiles).
The new scheduling will be realized in a couple of weeks once we upgrade our grids to Xen 3.3.
Let me know if you have any questions or if your problems are persisting, we want to fix them!
You guys keep us honest, and your comments ensure that we provide the high-quality service that this community has come to expect from the RapidXen brand.
William,
Thanks for the reply. I wish I knew about the Chicago issue while hosting there. My node had “performance issues” from day one, and after configuring the box as a monitoring node, it was simply un-usable so I canceled without even submitting a ticket. I understand it takes a while between symptoms developming, to the issue being identified, to a fix being implemented, but a little proactive “we’re seeing issues and working to resolve them” may have helped keep me there. Not bashing, just suggesting. 🙂
While writing this, I just logged into my RapidXen support account and found your comments. Thank you for the explanations and other considerations. To those reading: Seems the host for my Fremond node was plagued by a bad Cat6 cable and/or connection, which should now be resolved. That definitely explains the network issues I’ve been having over the last week.
William, I understand in this industry you’re more likely to get bad press than good, complaints than complements, so I appreciate your above response. I only posted in the tone that I did, because of the support ticket I got back denied a problem despite the Nagios log I pasted in the response. After your diligence in looking further into the matter, and now that everything seems resolved, and I haven’t seen a problem today, I’m still a happy customer. 🙂