 In the world of database systems, SQL has been the king since it took off in the early 80s. It was conceived, developed, and codified in the 1970s but really hit its stride once developers had worked out the kinks and it rapidly overtook earlier, hierarchical DB systems like IMS.
In the world of database systems, SQL has been the king since it took off in the early 80s. It was conceived, developed, and codified in the 1970s but really hit its stride once developers had worked out the kinks and it rapidly overtook earlier, hierarchical DB systems like IMS.
In the 21st century, NoSQL databases have emerged. What’s the difference? Is SQL going to be eclipsed by NoSQL? No because they’re really two different systems with different strengths. Indeed, as it turns out, you can do a lot of NoSQL in SQL.
What is SQL?
SQL is the Structured Query Language (not the Standard Query Language). It was popularized by products such as Oracle, IBM’s DB/2, Microsoft’s SQL Server, MySQL, and PostgreSQL. SQL stores and represents data in tables, which are analogous to spreadsheets.
For example, let’s say you have an inventory of cars you are selling. Your table might look like this:
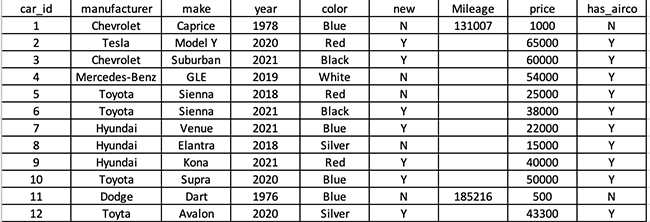
Note that missing values (called NULLs) are OK. It just means there’s no data for that row and the application can decide how it wants to deal with it.
From this table (we’ll call it ‘car_inventory’), it is very easy to do searches.
-- For example, to find used cars: SELECT * FROM car_inventory WHERE new = 'N'; -- You can sort if you wish: SELECT * FROM car_inventory WHERE new = 'N' ORDER BY manufacturer, make; You can also do various summary functions easily. For example: -- number of cars in your inventory: SELECT COUNT(*) FROM car_inventory; -- how many cars in your inventory -- how many cars in your inventory that are made by Toyota: SELECT COUNT(*) FROM car_inventory WHERE manufacturer = 'Toyota'; -- total value SELECT SUM (price) from car_inventory; -- most expensive car SELECT make, manufacturer, year FROM car_inventory WHERE price = MAX(price);
etc. SQL excels at finding data with filters and also in summarizing data (or “slicing and dicing”) it. This is obviously a quick example but imagine if you are Wal-mart and have an inventory question. Asking queries like “how much toothpaste of all brands did we sell in South Dakota in January”, “how many size 12 red sneakers do we have in stock in store 1234”, and “give me a report of sales of diet soda by region and by time of day for these three months from people who also bought potato chips” are easy to do.
SQL Weaknesses
Notice that “has_airco” column. I could filter on that and find cars that have or don’t have airco. But what if I also wanted to keep track of cars that have side impact airbags, Apple Airplay, leather seats, seat warmers, etc.? I could find myself with hundreds of columns, one for each feature.
There are ways of dealing with this. Typically you’d split this table into multiple other tables, perhaps with one called “seat_features” with a smaller number of columns, and then join the tables together (using the car_id to make sure the right rows are joined with the right rows).
But what if tomorrow a company comes out with a new feature and you start getting cars with that feature? You have to go in and edit the structure of your tables before you can load that data. Obviously, SQL is best when you have a defined set of attributes for your data.
SQL also has a couple other drawbacks. Simple queries like those shown above are almost English-like and easy to grasp. But in complex databases these can grow into queries so complex you need software to help you sort out what’s going on:
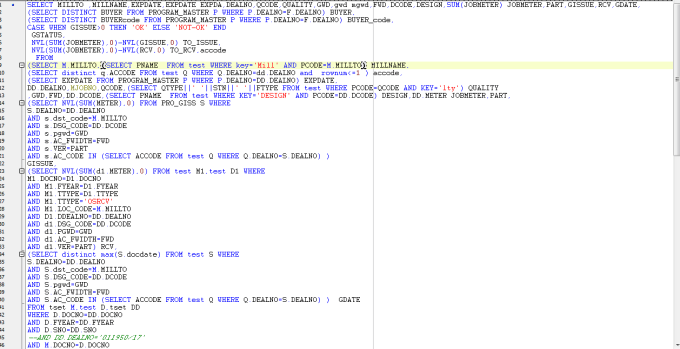
SQL is a string-based language, so it’s not well-suited for serializing/deserializing objects, though many SQL DBs now have proper JSON support (see below) and some support binary BLOBs.
Finally, SQL is premised on the idea that clients will use SQL as designed – to give it a query and have it produce a result set. Many developers have a mindset of “give it to me row by row so I can decide what to do” which results in many open queries and cursors that can slow performance. Or put another way: many developers don’t spend the time required to master SQL because other things compete with their time, so they tend to write poor queries.
So What is NoSQL?
NoSQL is a sort of “coat check” system. Imagine you’re going to an event and go to the coat check counter. You had them your article and they give you a ticket, number 4173. When you return later, you give them your ticket, and they give your article back.
Ticket 4173 can be anything: a trench coat, a fur stole, a woman’s purse, a backpack, etc. The clerk doesn’t have to redesign their system if I give them a windbreaker as opposed to a leather vest. Everything revolves around the paradigm of “give me whatever 4173 represents”.
In computing, 4173 is a document ID and what you get is data such as a JSON document (or it could be an XML document or really any format). It’s very fast to say “give me document 4173” and the application then does with the JSON document whatever it wants. If the document has 25 fields and the application adds 3 more and then checks it in again, the database is not going to balk.
This is a great approach when doing development because there’s no need to constant change the database structure before you add or modify data. Columns don’t grow stale because there are no columns.
But there are drawbacks:
- Getting summary data is very expensive. For example, if we had our cars inventory in a NoSQL database, it would be difficult to count how many are Toyotas. We’d have to check out all the documents and examine each one. I can ameliorate this somewhat with indexing but in general, NoSQL is a “fetch me this document” model, not a “search for this data” model.
- The slicing, dicing, etc. is not possible. I can’t give complex criteria and ask the DB for matching rows.
So Which is Better?
Neither. They’re just different models. In some cases, NoSQL is excellent. In some cases, SQL is a better choice.
And many systems use both. For example, imagine an online RPG. I might store accounting information about the player (player ID, name, email, password hash, etc.) in a SQL database. Then if I want to fetch his character, I fetch that player ID document in the NoSQL database and get JSON objects I can use to easily load into the game.
Or I may have an order management system where all the summary data, statistics, and basic customer information is in SQL, but each order placed is in a NoSQL database. Etcetera.
Can I do NoSQL in SQL?
Yes, and this is increasingly common. You can create a table with frequently accessed/summarized columns, and then a column (or a separate table joined by ID) with JSON data. If you don’t want the whole document, many RDBMS systems have JSON functions that will parse the JSON in the engine and return a specific field, or index that field.
A Final Note on Availability and Consistency
Another design factor is consistency. SQL originally ran on single servers where data could be trusted to be consistent, and it uses multi-version concurrency control and ACID promises to ensure that no one is reading half-written data even if there are hundreds of readers/writers, even if a single transaction spans hundreds of tables.
However, historically it’s been more difficult to make read/write SQL systems highly available and not dependent on a single server. There are replication approaches, but these can be dangerous if someone commits a write on one server and then someone queries another before replication is complete. While were are expensive proprietary solutions to the problem (e.g., Oracle’s Real Application Clusters) many enterprises opt for a failover approach, where if a system crashes, a clustered node picks up it’s SAN-shared or replication copy of the database and becomes the database server. However, this usually incurs a period of downtime while the failover happens.
Not all database systems need this level of “always available, always consistent” protection. A classic example is a social networking site where if I see a post has 73 likes and at the same time you see it has 74 likes, who cares? “Eventual” consistency in this case may be more important than complete consistency. The CAP theorum explains the trade-offs.
Related Posts:
Why Oracle's Trouble in Wisconsin Is a Big Deal
The Era of Vibe-Coded Operating Systems is Upon Us
Programming Languages I Have Known and Loved (and Hated)
MySQL and MariaDB: Dead Code Walking
Oracle Database 26ai is Coming Out in January. You Don't Need It. But There's a Free Version.
NameCrane Offloaded SQL: Get Hosted MySQL in the Cloud for Very Cheap!
raindog308 is a longtime community LETizen, technical writer, and self-described techno polymath. With deep roots in the *nix world, he has a passion for systems both modern and vintage, ranging from Unix, Perl, Python, and Golang to shell scripting and mainframe-era operating systems like MVS. He’s equally comfortable with relational database systems, having spent years working with Oracle, PostgreSQL, and MySQL.
As an avid user of LowEndBox providers, raindog308 runs an empire of LEBs, from tiny boxes for VPNs, to mid-sized instances for application hosting, and heavyweight servers for data storage and complex databases. He brings both technical rigor and real-world experience to every piece he writes.
Beyond the command line, raindog308 has a life-long love of German Shepherd Dogs, high-quality knives, target shooting, theology, tabletop RPGs, playing guitar, and hiking in deep, quiet forests.
His goal with every article is to help users, from beginners to seasoned sysadmins, get more value, performance, and enjoyment out of their infrastructure.
You can find him daily in the forums at LowEndTalk under the handle @raindog308.


























Leave a Reply