 In part one of this tutorial (“Run Your Own AI LLM Model on a LowEnd VPS for $2.49 a Month! Part One: Ollama and the Model“), we discussed quantization a little, then showed you how to setup Ollama and choose an appropriate large language model to run on it.
In part one of this tutorial (“Run Your Own AI LLM Model on a LowEnd VPS for $2.49 a Month! Part One: Ollama and the Model“), we discussed quantization a little, then showed you how to setup Ollama and choose an appropriate large language model to run on it.
Now we’re going to make it a little bit more user-friendly by installing a web UI.
Special thanks to LowEndTalk member @oloke for helping out with a Docker question while writing this tutorial.
The VPS
I’m going to be using a RackNerd VPS with these specs:
- 3 vCPU Cores
- 60 GB Pure SSD Storage
- 3.5 GB RAM
- 5TB Monthly Transfer
- Only $29.89/YEAR!
That’s only $2.49/month which is a fantastic deal. You can GET YOUR OWN HERE. I placed mine in Los Angeles, CA but these are available in multiple datacenters in North America, including San Jose, Seattle, Chicago, Dallas, New York, Ashburn, and Toronto.
Ollama’s Modes
This may not be official, but I think of Ollama running in three modes.
First, there’s the “one shot” mode, where you type something like
ollama run tinyllama "explain the cost of living difference between paris and london"The model runs, you get your answer, and Ollama is done.
Second, you can run it interactively. You type
ollama run tinyllama
and then interact with the model, chatting back and forth. (See video in the previous article for an example).
Finally, Ollama can run as an API service, typically on port 11434, where you can post to/from it with properly formatted JSON. Using this latter method, we’ll connect a web UI to Ollama.
If you’re curious, this is what it looks like under the covers:
curl http://172.17.0.1:11434/api/generate \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "tinyllama",
"prompt": "If I invest $100 in a tax-deferred S&P 500 fund, how much will I have in 30 years?",
"stream": false
}'
which gives a response like this (I didn’t put this in <code> tags because otherwise it’d appear here as one very long line):
{“model”:”tinyllama”,”created_at”:”2025-08-04T23:52:51.508221703Z”,”response”:”To answer your question, let’s assume that you initially invested $100 into a tax-deferred S\u0026P 500 (or other stock index) mutual fund. Here are some assumptions for how the fund’s investments will perform:\n\n- Assuming an annual return of 7%, which is the average annual return of a S\u0026P 500 fund over the past decade, you would expect to have $14,236 (in $100 terms) after 30 years.\n- This assumes that inflation is not present and the purchasing power of your investment increases by a factor of about 2.35 every year.\n- You would also need to pay taxes on this income at the average federal capital gains rate (currently 14.0%) each year, which would push your final sum down by $687 ($14,236 – $14,723).\n\nHowever, keep in mind that actual returns may be lower or higher depending on various factors such as stock market volatility and inflation rates over time.”,”done”:true,”done_reason”:”stop”,”context”:[529,29989,5205,29989,29958,13,3492,526,263,8444,319,29902,20255,29889,2,29871,13,29966,29989,1792,29989,29958,13,3644,306,13258,395,29896,29900,29900,297,263,8818,29899,1753,3127,287,317,29987,29925,29871,29945,29900,29900,5220,29892,920,1568,674,306,505,297,29871,29941,29900,2440,29973,2,29871,13,29966,29989,465,22137,29989,29958,13,1762,1234,596,1139,29892,1235,29915,29879,5251,393,366,12919,13258,287,395,29896,29900,29900,964,263,8818,29899,1753,3127,287,317,29987,29925,29871,29945,29900,29900,313,272,916,10961,2380,29897,5478,950,5220,29889,2266,526,777,20813,363,920,278,5220,29915,29879,13258,1860,674,2189,29901,13,13,29899,17090,385,17568,736,310,29871,29955,13667,607,338,278,6588,17568,736,310,263,317,29987,29925,29871,29945,29900,29900,5220,975,278,4940,1602,1943,29892,366,723,2149,304,505,395,29896,29946,29892,29906,29941,29953,313,262,395,29896,29900,29900,4958,29897,1156,29871,29941,29900,2440,29889,13,29899,910,15894,393,4414,362,338,451,2198,322,278,10596,5832,3081,310,596,13258,358,16415,491,263,7329,310,1048,29871,29906,29889,29941,29945,1432,1629,29889,13,29899,887,723,884,817,304,5146,8818,267,373,445,17869,472,278,6588,17097,7483,11581,29879,6554,313,3784,368,29871,29896,29946,29889,29900,10997,1269,1629,29892,607,723,5503,596,2186,2533,1623,491,395,29953,29947,29955,3255,29896,29946,29892,29906,29941,29953,448,395,29896,29946,29892,29955,29906,29941,467,13,13,17245,29892,3013,297,3458,393,3935,3639,1122,367,5224,470,6133,8679,373,5164,13879,1316,408,10961,9999,1700,2219,19411,29891,322,4414,362,19257,975,931,29889],”total_duration”:13847188395,”load_duration”:1401758180,”prompt_eval_count”:68,”prompt_eval_duration”:1662628060,”eval_count”:243,”eval_duration”:10780731002}
Install Docker and Docker Compose
We’re going to use OpenWebui and run it via Docker. so first, let’s install Docker:
apt update
apt -y install docker.io docker-compose
systemctl enable --now dockerCreate Project Directory
mkdir -p /opt/open-webui && cd /opt/open-webui
Create docker-compose.yml
Create and edit the file:
vi docker-compose.yml
Paste the following:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- open-webui:/app/backend/data
ports:
- ${OPEN_WEBUI_PORT-3000}:8080
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11434
- DEBUG=true
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
open-webui: {}Start it up:
docker-compose up -dInstall Nginx and Certbot
apt -y install nginx certbot python3-certbot-nginxConfigure Nginx Reverse Proxy
Create a config file, replacing ai.lowend.party with your domain:
/etc/nginx/sites-available/ai.lowend.party
Paste this
server {
listen 80;
server_name ai.lowend.party;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# see comment on these three lines below
proxy_buffering off;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
Regarding the three proxy_ lines after the comment…initially I was getting errors like this from Open Webui:
SyntaxError: JSON.parse: unexpected character at line 1 column 1 of the JSON
There is a GitHub issue that addresses this, and the three lines mentioned above fix it. If you run into other issues, that issue is a gold mine of discussion on this problem with many different solutions offered.
Enable the config:
ln -s /etc/nginx/sites-available/ai.lowend.party /etc/nginx/sites-enabled/
nginx -t
systemctl reload nginx
Enable HTTPS with Let’s Encrypt
certbot --nginx -d ai.lowend.partyOllama and Docker
You’ll need to tweak the Ollama systemd unit file to work properly. Edit /etc/systemd/system/ollama.service and add the bolded line:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" Environment="OLLAMA_HOST=172.17.0.1:11434" [Install] WantedBy=default.target
This will tell Ollama to run on the docker0 bridge network.
Restart Ollama:
systemctl daemon-reload systemctl start ollama
Important Note: if you want to run Ollama on the command line after making this change, you’ll need to prepend your commands as follows:
OLLAMA_HOST=172.17.0.1:11434 ollama run tinyllamaTry Out the Web Interface
Now browse to your URL (in this case, https://ai.lowend.party):

Create your admin account as prompted, and then you’ll be in the main interface:
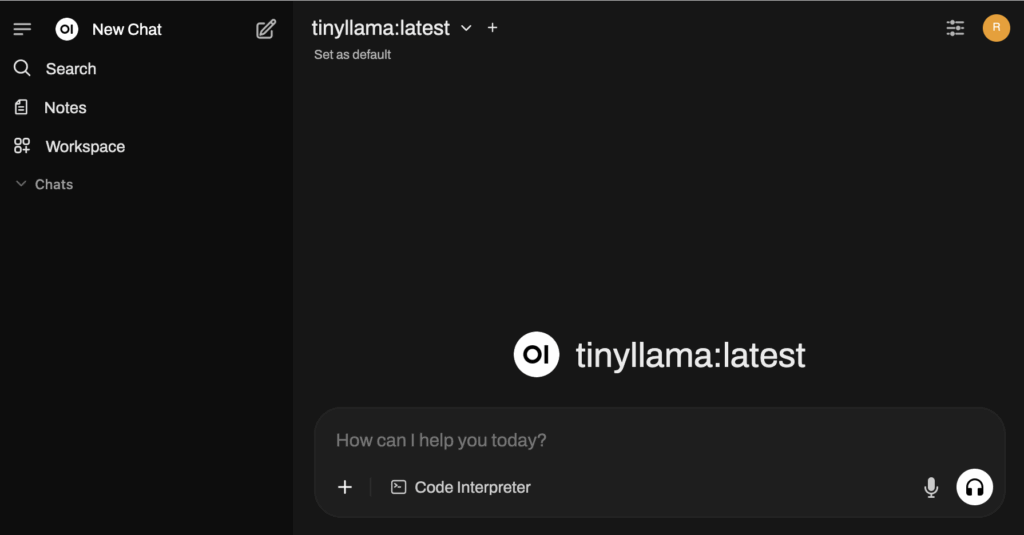
You’ll notice that at the top, TinyLlama is selected. If you were to install more models, you could select them from the drop down.
On the left, just like ChatGPT, you will see your past chats. Let’s try one out:
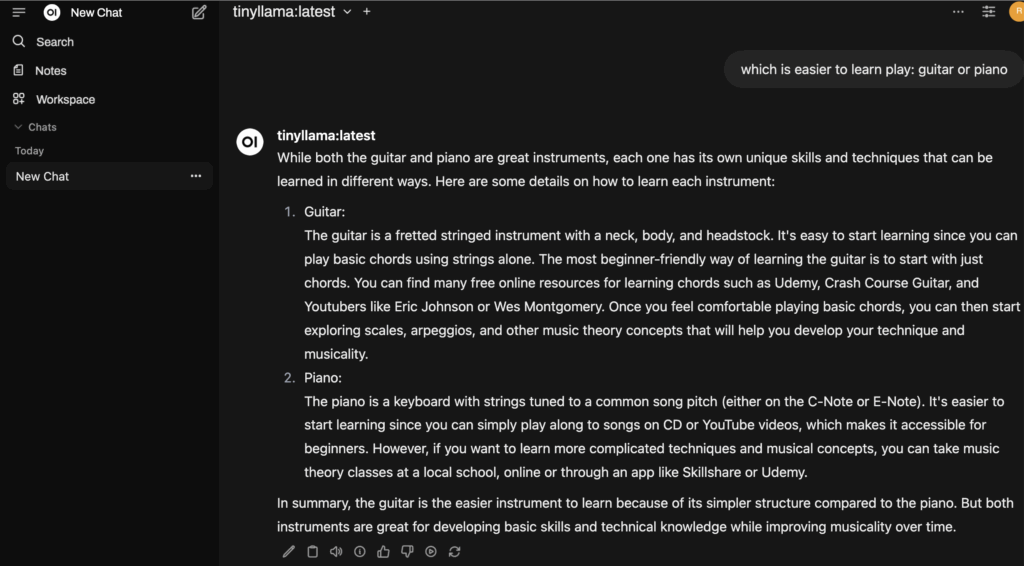
I completely disagree with TinyLlama here – guitar is a lot harder to learn – but that’s a matter of opinion.
Related Posts:
Is LowEndBox Written by AI? No!
HostNamaste: Dedicated Physical CPU • Enterprise SSD Storage • Windows & Linux • USA • Canada • Fran...
No Limit! New LowEndTalk Community Provider NolimitHost Has Some Nice Offers in Chicago and Frankfur...
ALMOST GONE! Get a BONUS CODE for ColoCrossing's Synology NAS, AirPods Max, Apple Watch, and MORE Gi...
Got Your Cheap Dedi Yet? Only $29/Month from ColoCrossing PLUS Here's a BONUS CODE to Help You Win a...
ServerHost Offers 16GB KVM VPS with 240GB NVMe for $99.99/year — Only 100 Codes Available
raindog308 is a longtime community LETizen, technical writer, and self-described techno polymath. With deep roots in the *nix world, he has a passion for systems both modern and vintage, ranging from Unix, Perl, Python, and Golang to shell scripting and mainframe-era operating systems like MVS. He’s equally comfortable with relational database systems, having spent years working with Oracle, PostgreSQL, and MySQL.
As an avid user of LowEndBox providers, raindog308 runs an empire of LEBs, from tiny boxes for VPNs, to mid-sized instances for application hosting, and heavyweight servers for data storage and complex databases. He brings both technical rigor and real-world experience to every piece he writes.
Beyond the command line, raindog308 has a life-long love of German Shepherd Dogs, high-quality knives, target shooting, theology, tabletop RPGs, playing guitar, and hiking in deep, quiet forests.
His goal with every article is to help users, from beginners to seasoned sysadmins, get more value, performance, and enjoyment out of their infrastructure.
You can find him daily in the forums at LowEndTalk under the handle @raindog308.


























Well, if you’re just trying to learn chords and strumming, then I guess TinyLlama has a valid point here! LOL!